Documentation Index
Fetch the complete documentation index at: https://futureagi.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
1. Installing The Depenencies
2. Configuring OpenAI to build our RAG App
3. Configuring FutureAGI SDK for Evaluation and Observability
We’ll use FutureAGI SDK for two main purposes:- Setting up an evaluator to run tests using FutureAGI’s evaluation metrics
- Initializing a trace provider to capture experiment data in FutureAGI’s Observability platform
The LangChainInstrumentor will automatically capture:
- LLM calls and their responses
- Embedding operations
- Document retrieval metrics
- Chain executions and their outputs
Viewing Experiment Results
After running your RAG application with the instrumented components, you can view comprehensive visibility into our project in the FutureAGI platform: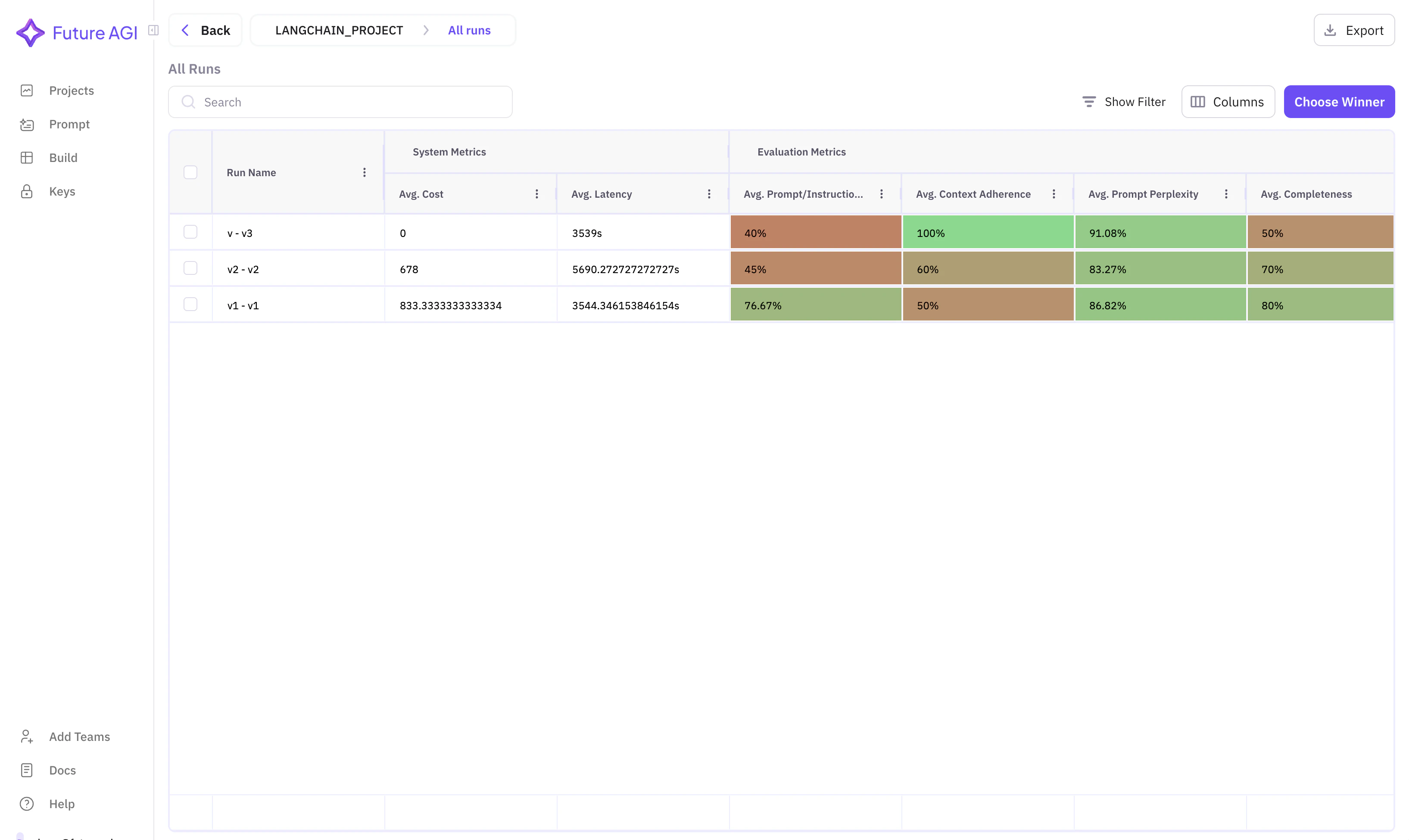
A sample Questionaire dataset for our RAG app which contains some query and also has a target context for our post build Evaluations
| Query_ID | Query_Text | Target_Context | Category |
|---|---|---|---|
| 1 | What are the key differences between the transformer architecture in ‘Attention is All You Need’ and the bidirectional approach used in BERT? | Attention is All You Need; BERT | Technical Comparison |
| 2 | Explain the positional encoding mechanism in the original transformer paper and why it was necessary. | Attention is All You Need | Technical Understanding |
4. RecursiveSplitter and Basic Retrieval
let’s set a basic RAG app using text_splitter from LangChain, and we will store the embeddings generated from OpenAI’s model in a ChromaDB which can be found in langchain_community library.We will then utilize our sample Questionaire dataset and feed it to our RAG App, to get answers for evaluation
Let’s Utilize these results and evaluate our RAG App using Future AGI SDK
Following Evals are beneficial to evaluate our RAG App and find the room for improvement if there is any.- ContextRelevance
- ContextRetrieval
- Groundedness
Using these functions we can get them
Semantic Chunker and Basic Embedding Retrieval
Now let’s try to improve our Chunking Logic as we scored fairly low in Context Retrieval, we will use the Semantic Chunk from LangChain’s Text Splitter for the document chunking which chunks based on the change of semantic embedding between the texts.Let’s Evaluate our App again
CHAIN OF THOUGHT
There is still a room for improvement for Groundedness Eval, therefore let’s change our Retrieval Logic, we will first pass a chain which tells the llm to break down sub questions based on the query and then use those sub-questions to retrieve the relevant context.Let’s Evaluate Our RAG App again for the same evals
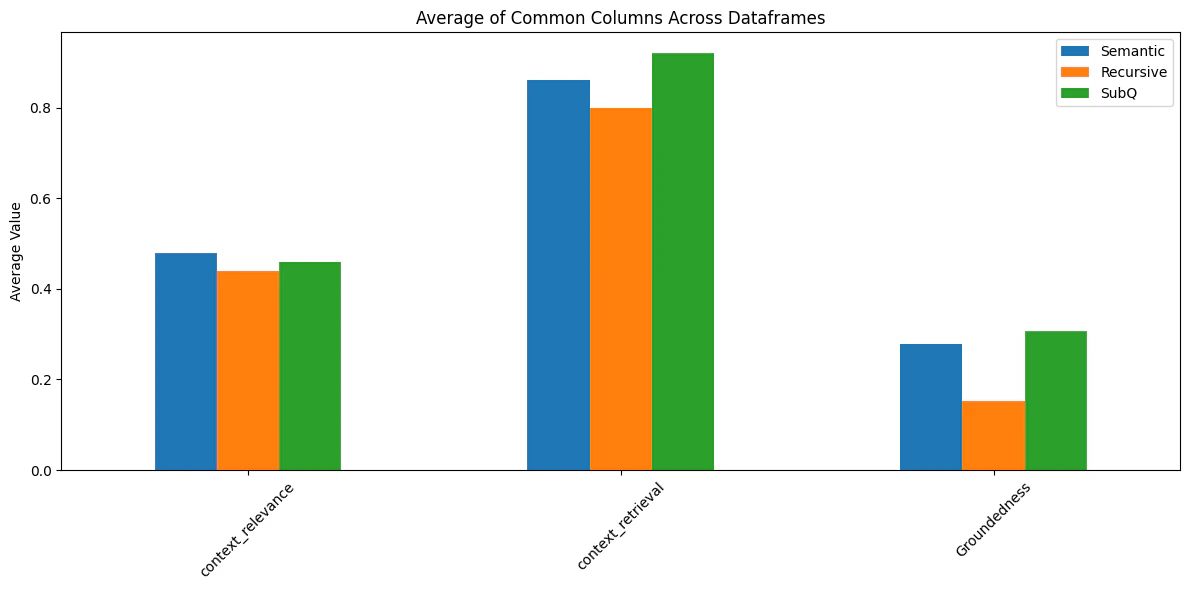
Results Analysis
The comparison of three different RAG approaches reveals:- Context Relevance:
- All approaches performed similarly (0.44-0.48)
- Semantic chunking slightly outperformed others at 0.48
- Context Retrieval:
- Chain of Thought (SubQ) approach showed best performance at 0.92
- Semantic chunking followed at 0.86
- Recursive splitting had the lowest score at 0.80
- Groundedness:
- Chain of Thought showed highest groundedness at 0.31
- Semantic chunking followed at 0.28
- Recursive splitting performed poorest at 0.15
Best Practices and Recommendations
Based on our experiments:- When to use each approach:
- Use Chain of Thought (SubQ) when dealing with complex queries requiring multiple pieces of information
- Use Semantic chunking for simpler queries where speed is important
- Recursive splitting works as a baseline but may not be optimal for production use
- Performance considerations:
- SubQ approach requires more API calls due to sub-question generation
- Semantic chunking has moderate computational overhead
- Recursive splitting is the most computationally efficient
- Cost considerations:
- SubQ approach may incur higher API costs due to multiple calls
- Consider caching mechanisms for frequently asked questions
Future Improvements
Potential areas for further enhancement:- Hybrid Approach:
- Combine semantic chunking with Chain of Thought for complex queries
- Use adaptive selection of approach based on query complexity
- Optimization Opportunities:
- Implement caching for sub-questions and their results
- Fine-tune chunk sizes and overlap parameters
- Experiment with different embedding models
- Additional Evaluations:
- Add response time measurements
- Include cost per query metrics
- Measure memory usage for each approach